Ko var atklāt ar dispersijas analīzi. Dispersijas analīze. ANOVA un Studenta un Fišera kritēriji: kurš ir labāks
Dispersijas analīze
1. Dispersijas analīzes jēdziens
Dispersijas analīze- šī ir pazīmes mainīguma analīze jebkuru kontrolētu mainīgo faktoru ietekmē. Ārzemju literatūrā dispersijas analīzi bieži dēvē par ANOVA, kas tulkojumā nozīmē dispersijas analīzi (dispersijas analīze).
Dispersijas analīzes uzdevums sastāv no cita veida mainīguma izolēšanas no pazīmes vispārējās mainīguma:
a) mainība katra pētītā neatkarīgā mainīgā darbības dēļ;
b) mainīgums pētīto neatkarīgo mainīgo mijiedarbības dēļ;
c) nejauša variācija visu pārējo nezināmo mainīgo dēļ.
Mainīgums pētīto mainīgo darbības un to mijiedarbības dēļ korelē ar nejaušu mainīgumu. Šīs attiecības rādītājs ir Fišera F tests.
Kritērija F aprēķina formula ietver dispersiju aplēses, tas ir, pazīmes sadalījuma parametrus, tāpēc kritērijs F ir parametrisks kritērijs.
Jo vairāk pazīmes mainīgums ir saistīts ar pētītajiem mainīgajiem (faktoriem) vai to mijiedarbību, jo augstāks kritērija empīriskās vērtības.
Nulle dispersijas analīzes hipotēze sacīs, ka pētītās efektīvās pazīmes vidējās vērtības visās gradācijās ir vienādas.
Alternatīva hipotēze apgalvos, ka efektīvā atribūta vidējās vērtības dažādās pētītā faktora gradācijās ir atšķirīgas.
Dispersijas analīze ļauj noteikt izmaiņas pazīmē, bet nenorāda virziensšīs izmaiņas.
Sāksim dispersijas analīzi ar vienkāršāko gadījumu, kad pētām tikai darbību viens mainīgais (viens faktors).
2. Vienvirziena dispersijas analīze nesaistītiem paraugiem
2.1. Metodes mērķis
Vienfaktoru dispersijas analīzes metodi izmanto gadījumos, kad efektīvā atribūta izmaiņas tiek pētītas mainīgu apstākļu vai jebkura faktora gradācijas ietekmē. Šajā metodes versijā katras faktora gradācijas ietekme ir savādāk testa priekšmetu paraugs. Jābūt vismaz trim faktora gradācijām. (Var būt divas gradācijas, taču šajā gadījumā mēs nevarēsim noteikt nelineāras atkarības un šķiet saprātīgāk izmantot vienkāršākas).
Šāda veida analīzes neparametrisks variants ir Kruskal-Wallis H tests.
Hipotēzes
H 0: atšķirības starp faktoru pakāpēm (dažādi apstākļi) nav izteiktākas par nejaušām atšķirībām katrā grupā.
H 1: atšķirības starp faktoru gradācijām (dažādi apstākļi) ir izteiktākas nekā nejaušās atšķirības katrā grupā.
2.2. Nesaistītu paraugu vienfaktoru dispersijas analīzes ierobežojumi
1. Vienfaktoru dispersijas analīzei nepieciešamas vismaz trīs faktora gradācijas un vismaz divi priekšmeti katrā gradācijā.
2. Rezultātā iegūtajai iezīmei ir jābūt normāli sadalītai pētījuma paraugā.
Tiesa, parasti netiek norādīts, vai runa ir par pazīmes sadalījumu visā aptaujātajā izlasē vai tajā tās daļā, kas veido dispersijas kompleksu.
3. Piemērs problēmas risināšanai ar viena faktora dispersijas analīzes metodi nesaistītiem paraugiem, izmantojot piemēru:
Trīs dažādas sešu priekšmetu grupas saņēma sarakstus ar desmit vārdiem. Pirmajai grupai vārdi tika pasniegti ar zemu ātrumu 1 vārds 5 sekundēs, otrajai grupai ar vidējo ātrumu 1 vārds 2 sekundēs un trešajai grupai ar augstu ātrumu 1 vārds sekundē. Tika prognozēts, ka reproducēšanas veiktspēja būs atkarīga no vārda prezentācijas ātruma. Rezultāti ir parādīti tabulā. 1.
Reproducēto vārdu skaits 1. tabula
|
priekšmeta numurs |
zems ātrums |
Vidējais ātrums |
liels ātrums |
|
kopējā summa |
|||
H 0: vārdu apjoma atšķirības starp grupas nav izteiktākas par nejaušām atšķirībām iekšā katra grupa.
H1: Vārda apjoma atšķirības starp grupas ir izteiktākas nekā nejaušās atšķirības iekšā katra grupa. Izmantojot tabulā norādītās eksperimentālās vērtības. 1, mēs noteiksim dažas vērtības, kas būs nepieciešamas, lai aprēķinātu kritēriju F.
Galveno lielumu aprēķins vienvirziena dispersijas analīzei ir parādīts tabulā:
2. tabula
3. tabula
Darbību secība vienvirziena ANOVA atvienotiem paraugiem

Šajā un turpmākajās tabulās bieži lietotais apzīmējums SS ir saīsinājums vārdam "kvadrātu summa". Šo saīsinājumu visbiežāk izmanto tulkotajos avotos.
SS fakts nozīmē pazīmes mainīgumu pētāmā faktora darbības dēļ;
SS kopīgs- pazīmes vispārējā mainīgums;
S CA- mainīgums, ko izraisa neņemti faktori, "gadījuma" vai "atlikuma" mainīgums.
JAUNKUNDZE- "vidējais kvadrāts" vai kvadrātu summas matemātiskā cerība, atbilstošā SS vidējā vērtība.
df - brīvības pakāpju skaits, ko, ņemot vērā neparametriskos kritērijus, apzīmējām ar grieķu burtu v.
Secinājums: H 0 ir noraidīts. H 1 ir pieņemts. Vārdu reproducēšanas apjoma atšķirības starp grupām ir izteiktākas nekā nejaušās atšķirības katrā grupā (α=0,05). Tātad vārdu pasniegšanas ātrums ietekmē to reproducēšanas apjomu.
Tālāk ir parādīts problēmas risināšanas piemērs programmā Excel:
Sākotnējie dati:

Izmantojot komandu: Rīki-> Datu analīze-> Vienvirziena dispersijas analīze, mēs iegūstam šādus rezultātus:

Dispersijas analīze ir iegūtās pazīmes mainīguma analīze jebkuru kontrolētu mainīgo faktoru ietekmē. (Ārzemju literatūrā to sauc par ANOVA - "Analisis of Variance").
Efektīvo pazīmi sauc arī par atkarīgo pazīmi, bet ietekmējošos faktorus par neatkarīgajām pazīmēm.
Metodes ierobežojums: neatkarīgas pazīmes var izmērīt pēc nominālās, kārtas vai metriskās skalas, atkarīgās pazīmes var izmērīt tikai metriskajā skalā. Lai veiktu dispersijas analīzi, tiek izdalītas vairākas faktoru raksturlielumu gradācijas, un visi izlases elementi tiek grupēti atbilstoši šīm gradācijām.
Hipotēžu formulēšana dispersijas analīzē.
Nulles hipotēze: "efektīvās pazīmes vidējās vērtības visos faktora apstākļos (vai faktoru gradācijas) ir vienādas."
Alternatīva hipotēze: "Efektīvās pazīmes vidējās vērtības dažādos faktora darbības apstākļos ir atšķirīgas."
Dispersijas analīzi var iedalīt vairākās kategorijās atkarībā no:
par aplūkoto neatkarīgo faktoru skaitu;
par faktoru iedarbībai pakļauto efektīvo mainīgo lielumu skaitu;
par salīdzināmo vērtību paraugu raksturu, iegūšanas raksturu un attiecību esamību.
Viena faktora klātbūtnē, kura ietekme tiek pētīta, dispersijas analīzi sauc par viena faktora analīzi un iedala divās šķirnēs:
- Nesaistītu (tas ir, atšķirīgu) paraugu analīze . Piemēram, viena respondentu grupa problēmu risina klusumā, otra – trokšņainā telpā. (Šajā gadījumā, starp citu, nulles hipotēze izklausītos šādi: “vidējais laiks šāda veida problēmu risināšanai būs vienāds klusumā un trokšņainā telpā”, tas ir, tas nav atkarīgs no trokšņa faktors.)
- Saistītā paraugu analīze , tas ir, divi mērījumi, kas veikti vienai un tai pašai respondentu grupai dažādos apstākļos. Tas pats piemērs: pirmo reizi uzdevums tika atrisināts klusumā, otrajā - līdzīgs uzdevums - trokšņa traucējumu klātbūtnē. (Praksē šādiem eksperimentiem jāpieiet piesardzīgi, jo var stāties vērā neņemts “apgūstamības” faktors, kura ietekmi pētnieks riskē attiecināt uz apstākļu maiņu, proti, troksni.)
Ja tiek pētīta divu vai vairāku faktoru vienlaicīga ietekme, mums ir darīšana ar daudzfaktoru dispersijas analīze, ko var arī iedalīt sīkāk pēc izlases veida.
Ja faktori ietekmē vairākus mainīgos, tad runa ir par daudzfaktoru analīze . Daudzfaktoru dispersijas analīze ir vēlama, nevis viendimensionāla, tikai tad, ja atkarīgie mainīgie nav neatkarīgi viens no otra un korelē viens ar otru.
Kopumā dispersijas analīzes uzdevums ir izdalīt trīs konkrētas dispersijas no pazīmes vispārējās mainīguma:
mainība katra no pētītā neatkarīgā mainīgā (faktora) darbības dēļ.
mainīgums pētāmo neatkarīgo mainīgo mijiedarbības dēļ.
mainība ir nejauša visu neņemto apstākļu dēļ.
Lai novērtētu mainīgumu pētāmo mainīgo darbības un to mijiedarbības dēļ, tiek aprēķināta atbilstošā mainīguma un nejaušības mainīguma rādītāja attiecība. Šīs attiecības rādītājs ir F - Fišera kritērijs.
Jo vairāk pazīmes mainīgums ir saistīts ar ietekmējošo faktoru darbību vai to mijiedarbību, jo augstākas ir kritērija empīriskās vērtības  .
.
Uz kritērija aprēķina formulu  dispersiju aplēses ir iekļautas, un tāpēc šī metode ietilpst parametrisko kategorijā.
dispersiju aplēses ir iekļautas, un tāpēc šī metode ietilpst parametrisko kategorijā.
Neatkarīgu paraugu vienvirziena dispersijas analīzes neparametrisks analogs ir Kruskal-Wallace tests. Tas ir līdzīgs Manna-Vitnija testam diviem neatkarīgiem paraugiem, izņemot to, ka tas summē katra no  grupas.
grupas.
Turklāt dispersijas analīzē var izmantot mediānas kritēriju. Izmantojot to, katrai grupai tiek noteikts novērojumu skaits, kas pārsniedz visām grupām aprēķināto mediānu, un novērojumu skaits, kas ir mazāks par mediānu, pēc kā tiek veidota divdimensiju nejaušības tabula.
Frīdmena tests ir neparametrisks pāra t-testa vispārinājums paraugiem ar atkārtotiem mērījumiem, kad salīdzināmo mainīgo skaits ir lielāks par diviem.
Atšķirībā no korelācijas analīzes, dispersijas analīzē pētnieks balstās uz pieņēmumu, ka daži mainīgie darbojas kā ietekmējošie (saukti par faktoriem vai neatkarīgiem mainīgajiem), bet citi (rezultātās pazīmes vai atkarīgie mainīgie) ir šo faktoru ietekmē. Lai gan šāds pieņēmums ir pamatā matemātiskajām aprēķinu procedūrām, tas tomēr prasa piesardzību, secinot cēloni un sekas.
Piemēram, ja izvirzām hipotēzi par ierēdņa veiksmes atkarību no faktora H (sociālā drosme pēc Cattell), tad nav izslēgts arī pretējais: respondenta sociālā drosme var rasties (palielināties) kā viņa darba panākumu rezultāts - tas ir, no vienas puses. No otras puses, vai mums ir jāapzinās, kā tieši tika mērīti “panākumi”? Ja tas balstījās nevis uz objektīviem raksturlielumiem (tagad modīgie “pārdošanas apjomi” utt.), bet gan uz kolēģu ekspertu vērtējumiem, tad pastāv iespēja, ka “veiksmi” var aizstāt ar uzvedības vai personiskām īpašībām (gribas, komunikatīvām, ārējām). agresivitātes izpausmes utt.).
Aplūkotā dispersijas analīzes shēma tiek diferencēta atkarībā no: a) pazīmes rakstura, pēc kuras populācija tiek sadalīta grupās (izlasēs); b) pazīmju skaita, pēc kuras populācija tiek sadalīta grupās (izlasēs). ); c) par paraugu ņemšanas metodi.
Funkciju vērtības. kas iedala populāciju grupās, var pārstāvēt vispārēju populāciju vai populāciju, kas ir tuvu tai. Šajā gadījumā dispersijas analīzes veikšanas shēma atbilst iepriekš aplūkotajai shēmai. Ja atribūta vērtības, kas veido dažādas grupas, ir paraugs no vispārējās populācijas, mainās nulles un alternatīvo hipotēžu formulējums. Kā nulles hipotēze tiek pieņemts, ka starp grupām pastāv atšķirības, tas ir, grupas vidējie rādītāji uzrāda dažas variācijas. Alternatīva hipotēze ir tāda, ka nepastāv nepastāvība. Acīmredzot ar šādu hipotēžu formulējumu nav pamata konkretizēt dispersiju salīdzināšanas rezultātus.
Palielinoties grupēšanas pazīmju skaitam, piemēram, līdz 2, pirmkārt, palielinās nulles un attiecīgi alternatīvo hipotēžu skaits. Šajā gadījumā pirmā nulles hipotēze norāda uz atšķirību neesamību starp vidējām vērtībām pirmās grupēšanas pazīmes grupām, otrā nulles hipotēze norāda uz atšķirību trūkumu otrās grupēšanas pazīmes grupām un, visbeidzot, trešā. nulles hipotēze norāda uz tā sauktā faktoru mijiedarbības efekta (grupēšanas pazīmju) neesamību.
Ar mijiedarbības efektu saprot tādas efektīvā atribūta vērtības izmaiņas, kuras nevar izskaidrot ar divu faktoru kopējo darbību. Lai pārbaudītu trīs izvirzītos hipotēžu pārus, ir jāaprēķina trīs F-Fišera kritērija faktiskās vērtības, kas savukārt nozīmē šādu kopējā variācijas apjoma paplašināšanas versiju.
Izkliedes, kas vajadzīgas, lai iegūtu F-kritēriju, tiek iegūtas zināmā veidā, dalot variācijas apjomus ar brīvības pakāpju skaitu.
Kā jūs zināt, paraugi var būt atkarīgi neatkarīgi. Ja izlases ir atkarīgas, tad kopējā variāciju apjomā jāizšķir tā sauktā atkārtojumu variācija  . Ja tas netiek izcelts, šī variācija var ievērojami palielināt grupas iekšējo variāciju (
. Ja tas netiek izcelts, šī variācija var ievērojami palielināt grupas iekšējo variāciju (  ), kas var izkropļot dispersijas analīzes rezultātus.
), kas var izkropļot dispersijas analīzes rezultātus.
Pārskatiet jautājumus
17-1.Kāda ir dispersijas analīzes rezultātu specifikācija?
17-2. Kādā gadījumā konkretizēšanai izmanto Q-Tukey kritēriju?
17-3 Kādas ir pirmā, otrā un tā tālāk pasūtījumu atšķirības?
17-4. Kā atrast Tjūkija Q kritērija faktisko vērtību?
17-5 Kādas ir hipotēzes katrai atšķirībai?
17-6. No kā ir atkarīga Tukey Q-testa tabulas vērtība?
17-7. Kāda būs nulles hipotēze, ja grupēšanas pazīmes līmeņi attēlo paraugu?
17-8 Kā tiek sadalīts kopējais variāciju apjoms, grupējot datus pēc diviem kritērijiem?
17-9. Kādā gadījumā izšķir atkārtojumu variācijas (  )
?
)
?
Kopsavilkums
Aplūkotais dispersijas analīzes rezultātu konkretizācijas mehānisms ļauj tam piešķirt gatavu formu. Lietojot Tukey Q-testu, jāpievērš uzmanība ierobežojumiem. Materiālā tika izklāstīti arī dispersijas analīzes modeļu klasifikācijas pamatprincipi. Jāuzsver, ka tie ir tikai principi. Katra modeļa iezīmju detalizētai izpētei ir nepieciešama atsevišķa dziļāka izpēte.
Testa uzdevumi lekcijai
Par kādiem statistiskajiem raksturlielumiem tiek izvirzītas hipotēzes dispersijas analīzē?
Attiecīgi pret divām dispersijām
Attiecībā uz vienu vidējo
Attiecībā uz vairākiem vidējiem rādītājiem
Attiecīgi pret vienu dispersiju
Kāds ir alternatīvās hipotēzes saturs dispersijas analīzē?
Salīdzināmas atšķirības nav vienādas viena ar otru
Visi salīdzinātie vidējie rādītāji nav vienādi viens ar otru
Vismaz divi vispārīgie līdzekļi nav vienādi
Starpgrupu dispersija ir lielāka nekā grupas iekšējā dispersija
Kādi nozīmīguma līmeņi visbiežāk tiek izmantoti dispersijas analīzē
Ja variācijas grupas iekšienē ir lielākas nekā starpgrupu variācijas, vai dispersijas analīze ir jāturpina vai mums nekavējoties jāpieņem H0 vai HA?
1. Vai mums vajadzētu turpināt, nosakot nepieciešamās novirzes?
2. Jāpiekrīt H0
3. Jāpiekrīt NA
Ja grupas iekšējā dispersija bija vienāda ar starpgrupu dispersiju, kādām vajadzētu būt ANOVA darbībām?
Piekrītiet nulles hipotēzei, ka populācijas vidējie rādītāji ir vienādi
Piekrītiet alternatīvajai hipotēzei par vismaz viena otrai nevienlīdzīgu līdzekļu pāra klātbūtni
Kādai dispersijai vienmēr jābūt skaitītājā, aprēķinot Fišera F testu?
Tikai grupas iekšienē
Jebkurā gadījumā starpgrupu
Intergroup, ja tas ir lielāks par iekšgrupu
Kādai jābūt F-Fisher kritērija faktiskajai vērtībai?
Vienmēr mazāk par 1
Vienmēr lielāks par 1
vienāds vai lielāks par 1
No kā ir atkarīga F-Fisher kritērija tabulas vērtība?
1. No pieņemtā nozīmīguma līmeņa
2. Par vispārējās variācijas brīvības pakāpju skaitu
3. Par starpgrupu variācijas brīvības pakāpju skaitu
4. Par iekšējās grupas variācijas brīvības pakāpju skaitu
5. No F-Fisher kritērija faktiskās vērtības vērtības?
Palielinot novērojumu skaitu katrā grupā ar vienādām novirzēm, palielinās iespēja pieņemt ……
1. Nulles hipotēze
2. Alternatīvā hipotēze
3. Neietekmē gan nulles, gan alternatīvās hipotēzes pieņemšanu
Kāda jēga precizēt dispersijas analīzes rezultātus?
Noskaidrojiet, vai dispersiju aprēķini tika veikti pareizi
Nosakiet, kurš no vispārējiem vidējiem rādītājiem izrādījās vienāds viens ar otru
Noskaidrojiet, kuri no vispārējiem vidējiem rādītājiem nav vienādi
Vai apgalvojums ir patiess: “Konkretizējot dispersijas analīzes rezultātus, visi vispārīgie vidējie rādītāji izrādījās viens otram vienādi”
Var būt patiess un nepatiess
Nav taisnība, tas var būt saistīts ar kļūdām aprēķinos
Vai, konkretizējot dispersijas analīzi, var nonākt pie secinājuma, ka visi vispārīgie vidējie rādītāji nav vienādi?
1. Pilnīgi iespējams
2. Iespējams izņēmuma gadījumos
3. Principā neiespējami.
4. Iespējama tikai tad, ja aprēķinos ir kļūdas
Ja saskaņā ar F-Fišera testu tika pieņemta nulles hipotēze, vai ir jāprecizē dispersijas analīze?
1. Obligāti
2. Nav nepieciešams
3.Pēc ANOVA ieskatiem
Kādā gadījumā dispersijas analīzes rezultātu konkretizēšanai izmanto Tūkija kritēriju?
1. Ja novērojumu skaits grupās (izlasēs) ir vienāds
2. Ja novērojumu skaits pa grupām (izlasēm) ir atšķirīgs
3. Ja ir paraugi gan ar vienādiem, gan nevienādiem skaitļiem
slinkums
Kas ir NSR, konkretizējot dispersijas analīzes rezultātus, pamatojoties uz Tukey kritēriju?
1. Vidējās kļūdas un kritērija faktiskās vērtības reizinājums
2. Vidējās kļūdas un kritērija tabulas vērtības reizinājums
3. Katras starpības attiecība starp parauga vidējo vērtību pret
vidējā kļūda
4. Atšķirība starp izlases vidējiem
Ja izlasi sadala grupās pēc 2 pazīmēm, cik avotos jāsadala vismaz kopējās pazīmes variācijas?
Ja novērojumi pa paraugiem (grupām) ir atkarīgi, cik avotos ir jāsadala kopējā variācija (grupēšanas atribūts viens)?
Kāds ir starpgrupu variāciju avots (cēlonis)?
laimes spēle
Laimes spēles un faktoru kopīga darbība
Faktora(-u) darbība
Tas kļūs skaidrs pēc dispersijas analīzes
Kāds ir grupas iekšējo variāciju avots (cēlonis)?
1. Laimes spēle
2. Laimes spēles un faktoru kopīgā darbība
3. Faktoru darbība (faktori)
4. Tas kļūs skaidrs pēc dispersijas analīzes
Kādu avota datu pārveidošanas metodi izmanto, ja raksturīgās vērtības ir izteiktas daļās?
Logaritms
sakņu ekstrakcija
Phi transformācija
8. lekcija Korelācija
anotācija
Vissvarīgākā metode pazīmju attiecību pētīšanai ir korelācijas metode. Šī lekcija atklāj šīs metodes saturu, pieejas šīs saiknes analītiskajai izpausmei. Īpaša uzmanība tiek pievērsta tādiem specifiskiem rādītājiem kā komunikācijas tuvuma rādītājiem
Atslēgvārdi
Korelācija. Mazākā kvadrāta metode. Regresijas koeficients. Determinācijas un korelācijas koeficienti.
Izskatāmie jautājumi
Komunikācijas funkcionālā un korelācija
Komunikācijas korelācijas vienādojuma konstruēšanas posmi. Vienādojuma koeficientu interpretācija
Hermētiskuma indikatori
Komunikācijas izlases rādītāju izvērtēšana
Moduļu vienība 1 Korelācijas būtība. Komunikācijas korelācijas vienādojuma veidošanas posmi, vienādojuma koeficientu interpretācija.
Moduļu vienības pētījuma mērķis un uzdevumi 1 sastāv no korelācijas pazīmju izpratnes. savienojuma vienādojuma konstruēšanas algoritma apguve, vienādojuma koeficientu satura izpratne.
Korelācijas būtība
Dabas un sociālajās parādībās ir divu veidu savienojumi - funkcionālais savienojums un korelācijas savienojums. Izmantojot funkcionālu savienojumu, katra argumenta vērtība atbilst stingri noteiktām (vienai vai vairākām) funkcijas vērtībām. Funkcionālās attiecības piemērs ir saistība starp apkārtmēru un rādiusu, ko izsaka ar vienādojumu  . Katra rādiusa vērtība r atbilst vienai apkārtmēra vērtībai L
.
Ar korelāciju katra faktora atribūta vērtība atbilst vairākām ne visai noteiktām iegūtā atribūta vērtībām. Korelācijas piemēri var būt attiecības starp personas svaru (rezultātā pazīme) un viņa augumu (faktoriālā pazīme), attiecības starp izlietotā mēslojuma daudzumu un ražu, starp piedāvāto preču cenu un daudzumu. Korelācijas avots ir fakts, ka, kā likums, reālajā dzīvē efektīvās pazīmes vērtība ir atkarīga no daudziem faktoriem, tostarp tiem, kuru izmaiņu raksturs ir nejaušs. Piemēram, vienāds cilvēka svars ir atkarīgs no vecuma, dzimuma, uztura, nodarbošanās un daudziem citiem faktoriem. Taču tajā pašā laikā ir skaidrs, ka kopumā tieši izaugsme ir izšķirošais faktors. Ņemot vērā šos apstākļus, korelācija definējama kā nepilnīga sakarība, kuru var konstatēt un novērtēt tikai tad, ja vidēji ir liels novērojumu skaits.
. Katra rādiusa vērtība r atbilst vienai apkārtmēra vērtībai L
.
Ar korelāciju katra faktora atribūta vērtība atbilst vairākām ne visai noteiktām iegūtā atribūta vērtībām. Korelācijas piemēri var būt attiecības starp personas svaru (rezultātā pazīme) un viņa augumu (faktoriālā pazīme), attiecības starp izlietotā mēslojuma daudzumu un ražu, starp piedāvāto preču cenu un daudzumu. Korelācijas avots ir fakts, ka, kā likums, reālajā dzīvē efektīvās pazīmes vērtība ir atkarīga no daudziem faktoriem, tostarp tiem, kuru izmaiņu raksturs ir nejaušs. Piemēram, vienāds cilvēka svars ir atkarīgs no vecuma, dzimuma, uztura, nodarbošanās un daudziem citiem faktoriem. Taču tajā pašā laikā ir skaidrs, ka kopumā tieši izaugsme ir izšķirošais faktors. Ņemot vērā šos apstākļus, korelācija definējama kā nepilnīga sakarība, kuru var konstatēt un novērtēt tikai tad, ja vidēji ir liels novērojumu skaits.
1.2 Komunikācijas korelācijas vienādojuma konstruēšanas posmi.
Tāpat kā funkcionāls savienojums, arī korelācijas savienojums tiek izteikts ar savienojuma vienādojumu. Lai to izveidotu, jums secīgi jāveic šādas darbības (posmi).
Pirmkārt, jums vajadzētu saprast cēloņu un seku attiecības, noskaidrot zīmju pakārtotību, tas ir, kuri no tiem ir cēloņi (faktoriālās pazīmes), un kuras ir sekas (efektīvās pazīmes). Cēloņu un seku attiecības starp pazīmēm nosaka subjekta teorija, kurā tiek izmantota korelācijas metode. Piemēram, zinātne par "cilvēka anatomiju" ļauj pateikt, kas ir svara un auguma attiecības avots, kura no šīm pazīmēm ir faktors, kurš rezultāts, "ekonomikas" zinātne atklāj attiecību loģiku starp cena un piedāvājums, nosaka, kas un kurā stadijā ir cēlonis un kāda ir sekas. Bez šāda sākotnējā teorētiskā pamatojuma vēlāk iegūto rezultātu interpretācija ir sarežģīta un dažkārt var novest pie absurdiem secinājumiem.
Konstatējot cēloņu un seku sakarību esamību, šīs attiecības pēc tam jāformalizē, tas ir, jāizsaka, izmantojot savienojuma vienādojumu, vispirms izvēloties vienādojuma veidu. Lai izvēlētos vienādojuma veidu, var ieteikt vairākas metodes. Var pievērsties priekšmeta teorijai, kur tiek izmantota korelācijas metode, piemēram, zinātnē "agroķīmija", iespējams, jau ir saņemta atbilde uz jautājumu, kuram vienādojumam jāizsaka sakarība: raža - mēslojums. Ja šādas atbildes nav, tad, lai izvēlētos vienādojumu, jāizmanto daži empīriski dati, tos attiecīgi apstrādājot. Uzreiz jāsaka, ka, izvēloties vienādojuma veidu, pamatojoties uz empīriskiem datiem, skaidri jāsaprot, ka ar šāda veida vienādojumu var aprakstīt izmantoto datu attiecības. Galvenais šo datu apstrādes paņēmiens ir grafiku konstruēšana, kad faktora atribūta vērtības tiek attēlotas uz abscisu ass, bet iespējamās efektīvā atribūta vērtības tiek attēlotas uz ordinātu ass. Tā kā pēc definīcijas viena un tā pati faktora atribūta vērtība atbilst efektīvā atribūta nenoteiktu vērtību kopai, iepriekš minēto darbību rezultātā mēs iegūsim noteiktu punktu kopu, ko sauc par korelācijas lauks. Kopējais korelācijas lauka skatījums atsevišķos gadījumos ļauj izdarīt pieņēmumu par vienādojuma iespējamo formu .. Mūsdienu datortehnoloģijām attīstoties, viena no galvenajām vienādojuma izvēles metodēm ir dažāda veida vienādojumu uzskaitīšana, savukārt vienādojums, kas nodrošina augstāko determinācijas koeficientu, ir izvēlēts par labāko, runa tiks aplūkota turpmāk. Pirms ķerties pie aprēķiniem, ir jāpārbauda, vai vienādojuma konstruēšanā izmantotie empīriskie dati atbilst noteiktām prasībām. Prasības attiecas uz faktoru raksturlielumiem un datu kopumu. Faktoru zīmēm, ja tās ir vairākas, jābūt vienai no otras neatkarīgām. Kas attiecas uz pildvielu, vispirms tam jābūt viendabīgam
(viendabīguma jēdziens tika aplūkots agrāk), un, otrkārt, tas ir diezgan liels. Katrai faktora zīmei jābūt vismaz 8-10 novērojumiem.
Pēc vienādojuma izvēles nākamais solis ir vienādojuma koeficientu aprēķināšana. Vienādojuma koeficientu aprēķins visbiežāk tiek veikts, pamatojoties uz mazāko kvadrātu metodi. No korelācijas viedokļa mazāko kvadrātu metodes izmantošana sastāv no tādu vienādojuma koeficientu iegūšanas,  =min, tas ir, lai rezultējošās pazīmes faktisko vērtību noviržu kvadrātā summa (
=min, tas ir, lai rezultējošās pazīmes faktisko vērtību noviržu kvadrātā summa (  ) no tiem, kas aprēķināti saskaņā ar vienādojumu (
) no tiem, kas aprēķināti saskaņā ar vienādojumu (  ) bija minimālā vērtība. Šī prasība tiek realizēta, konstruējot un atrisinot labi zināmu tā saukto normālo vienādojumu sistēmu. Ja, kā korelācijas vienādojumu starp y Un x ir izvēlēts taisnes vienādojums
) bija minimālā vērtība. Šī prasība tiek realizēta, konstruējot un atrisinot labi zināmu tā saukto normālo vienādojumu sistēmu. Ja, kā korelācijas vienādojumu starp y Un x ir izvēlēts taisnes vienādojums  , kur ir zināms, ka normālo vienādojumu sistēma ir:
, kur ir zināms, ka normālo vienādojumu sistēma ir: 

Šīs sistēmas atrisināšana priekš a Un b
,
iegūstam vajadzīgās koeficientu vērtības. Koeficientu aprēķināšanas pareizību pārbauda ar vienādību 
Kam izmanto dispersijas analīzi? Dispersijas analīzes mērķis ir izpētīt jebkura kvalitatīva vai kvantitatīvā faktora būtiskas ietekmes esamību vai neesamību uz pētāmās efektīvās pazīmes izmaiņām. Lai to izdarītu, faktors, kuram ir vai nav būtiska ietekme, tiek sadalīts gradācijas klasēs (citiem vārdiem sakot, grupās) un tiek noskaidrots, vai faktora ietekme ir vienāda, pārbaudot nozīmīgumu starp līdzekļiem. faktora gradācijām atbilstošās datu kopas. Piemēri: tiek pētīta uzņēmuma peļņas atkarība no izmantoto izejvielu veida (tad gradācijas klases ir izejvielu veidi), produkcijas vienības produkcijas pašizmaksas atkarība no uzņēmuma nodaļas lieluma ( tad gradācijas klases ir vienības lieluma pazīmes: liela, vidēja, maza).
Minimālais gradācijas klašu (grupu) skaits ir divas. Vērtēšanas klases var būt gan kvalitatīvas, gan kvantitatīvās.
Kāpēc dispersijas analīzi sauc par dispersijas analīzi? Dispersijas analīze pārbauda divu dispersiju attiecību. Izkliede, kā mēs zinām, ir datu izkliedes mērs ap vidējo. Pirmais ir dispersija, kas izskaidrojama ar faktora ietekmi, kas raksturo vērtību izkliedi starp faktoru gradācijām (grupām) ap visu datu vidējo vērtību. Otrais ir neizskaidrojama dispersija, kas raksturo datu izkliedi gradācijās (grupās) ap pašu grupu vidējām vērtībām. Pirmo dispersiju var saukt par starpgrupu, bet otro - par iekšējo grupu. Šo dispersiju attiecību sauc par faktisko Fišera koeficientu un salīdzina ar Fišera koeficienta kritisko vērtību. Ja faktiskā Fišera attiecība ir lielāka par kritisko, tad vidējās gradācijas klases atšķiras viena no otras un pētāmais faktors būtiski ietekmē datu izmaiņas. Ja mazāk, tad vidējās gradācijas klases viena no otras neatšķiras un faktoram nav būtiskas ietekmes.
Kā hipotēzes tiek formulētas, pieņemtas un noraidītas dispersijas analīzē? Dispersijas analīzē tiek noteikts viena vai vairāku faktoru kopējās ietekmes īpatnējais svars. Faktora ietekmes nozīmīgumu nosaka, pārbaudot hipotēzes:
- H0 : μ 1 = μ 2 = ... = μ a, Kur a- gradācijas klašu skaits - visām gradācijas klasēm ir viena vidējā vērtība,
- H1 : Ne viss μ i ir vienādi – ne visām gradācijas klasēm ir vienāda vidējā vērtība.
Ja faktora ietekme nav būtiska, tad arī šī faktora gradācijas klasēm atšķirība ir nenozīmīga un dispersijas analīzes gaitā nulles hipotēze H0 netiek noraidīts. Ja faktora ietekme ir nozīmīga, tad nulles hipotēze H0 noraidīts: ne visām gradācijas klasēm ir vienāds vidējais, tas ir, starp iespējamām atšķirībām starp gradācijas klasēm nozīmīga ir viena vai vairākas.
Vēl daži dispersijas analīzes jēdzieni. Statistiskais komplekss dispersijas analīzē ir empīrisko datu tabula. Ja visās gradāciju klasēs vienāds variantu skaits, tad statistisko kompleksu sauc par viendabīgu (homogēnu), ja variantu skaits ir atšķirīgs - par neviendabīgu (heterogēnu).
Atkarībā no aprēķināto faktoru skaita izšķir vienfaktoru, divfaktoru un daudzfaktoru dispersijas analīzi.
Vienvirziena dispersijas analīze: metodes būtība, formulas, piemēri
Metodes būtība, formulas
ir balstīts uz faktu, ka statistiskā kompleksa noviržu kvadrātu summu var sadalīt komponentos:
SS = SS a + SS e,
SS
SSa a noviržu kvadrātā summa,
SSe ir neizskaidrojama noviržu kvadrātā vai kļūdas noviržu kvadrātā summa.
Ja cauri ni norāda iespēju skaitu katrā gradācijas klasē (grupā) un a- kopējais faktora (grupu) gradāciju skaits, pēc tam - kopējais novērojumu skaits, un jūs varat iegūt šādas formulas:
kopējais kvadrātu noviržu skaits: ![]() ,
,
izskaidrojama ar faktora ietekmi a noviržu kvadrātā summa: ![]() ,
,
neizskaidrojama noviržu kvadrātā vai kļūdu kvadrātu summa: ![]() ,
,
![]() - kopējais novērojumu vidējais rādītājs,
- kopējais novērojumu vidējais rādītājs,
(grupa).
Turklāt,

kur ir faktora (grupas) gradācijas dispersija.
Lai veiktu statistiskā kompleksa datu vienvirziena dispersijas analīzi, jāatrod faktiskais Fišera koeficients - dispersijas attiecība, kas izskaidrojama ar faktora ietekmi (starpgrupa) un neizskaidrojamu dispersiju (iekšgrupa):
un salīdziniet to ar Fišera kritisko vērtību.
Novirzes tiek aprēķinātas šādi:
izskaidrota dispersija,
neizskaidrojama dispersija,
va = a − 1 ir izskaidrotās dispersijas brīvības pakāpju skaits,
ve= n − a ir neizskaidrojamās dispersijas brīvības pakāpju skaits,
v = n
Fišera koeficienta kritisko vērtību ar noteiktām nozīmīguma līmeņa un brīvības pakāpju vērtībām var atrast statistikas tabulās vai aprēķināt, izmantojot MS Excel F.OBR funkciju (attēls zemāk, lai to palielinātu, noklikšķiniet uz tā ar peles kreiso pogu).

Funkcijai ir jāievada šādi dati:
Varbūtības – nozīmīguma līmenis α ,
pakāpes_brīvības_1 - izskaidrotās dispersijas brīvības pakāpju skaits va,
pakāpes_brīvības_2 — neizskaidrojamas dispersijas brīvības pakāpju skaits ve.
Ja Fišera koeficienta faktiskā vērtība ir lielāka par kritisko vērtību (), tad nulles hipotēze tiek noraidīta ar nozīmīguma līmeni α . Tas nozīmē, ka faktors būtiski ietekmē datu izmaiņas un dati ir atkarīgi no faktora ar varbūtību P = 1 − α .
Ja Fišera koeficienta faktiskā vērtība ir mazāka par kritisko (), tad nulles hipotēzi nevar noraidīt ar nozīmīguma līmeni α . Tas nozīmē, ka faktors būtiski neietekmē datus ar varbūtību P = 1 − α .
Vienvirziena ANOVA: piemēri
1. piemērs Nepieciešams noskaidrot, vai izmantoto izejvielu veids ietekmē uzņēmuma peļņu. Sešās faktora gradācijas klasēs (grupās) (1. tips, 2. tips utt.) tika apkopoti dati par peļņu no 1000 produkcijas vienību ražošanas miljonos rubļu 4 gadu laikā.
| Izejvielu veids | 2014 | 2015 | 2016 | 2017 |
| 1 | 7,21 | 7,55 | 7,29 | 7,6 |
| 2 | 7,89 | 8,27 | 7,39 | 8,18 |
| 3 | 7,25 | 7,01 | 7,37 | 7,53 |
| 4 | 7,75 | 7,41 | 7,27 | 7,42 |
| 5 | 7,7 | 8,28 | 8,55 | 8,6 |
| 6 | 7,56 | 8,05 | 8,07 | 7,84 |
| Vidēji | Izkliede |
| 7,413 | 0,0367 |
| 7,933 | 0,1571 |
| 7,290 | 0,0480 |
| 7,463 | 0,0414 |
| 8,283 | 0,1706 |
| 7,880 | 0,0563 |
a= 6 un katrā klasē (grupā) ni = 4 novērojumiem. Kopējais novērojumu skaits n = 24 .
Brīvības pakāpju skaitļi:
va = a − 1 = 6 − 1 = 5 ,
ve= n − a = 24 − 6 = 18 ,
v = n − 1 = 24 − 1 = 23 .




Aprēķināsim novirzes:
![]()
![]() .
.
![]() .
.
Tā kā faktiskā Fišera attiecība ir lielāka par kritisko:
ar nozīmīguma līmeni α = 0,05 secinām, ka uzņēmuma peļņa atkarībā no ražošanā izmantoto izejvielu veida būtiski atšķiras.
Vai arī, kas ir tas pats, mēs noraidām galveno hipotēzi par vidējo vienlīdzību visās faktoru gradācijas klasēs (grupās).
Tikko aplūkotajā piemērā katrai faktoru gradācijas klasei bija vienāds opciju skaits. Bet, kā minēts ievaddaļā, iespēju skaits var būt atšķirīgs. Un tas nekādā veidā nesarežģī dispersijas analīzes procedūru. Šis ir nākamais piemērs.
2. piemērs Jānoskaidro, vai pastāv produkcijas vienības izmaksu atkarība no uzņēmuma vienības lieluma. Koeficients (apakšnodaļas vērtība) ir sadalīts trīs gradācijas klasēs (grupās): mazs, vidējs, liels. Tiek apkopoti šīm grupām atbilstošie dati par viena un tā paša veida preces vienības izlaides izmaksām noteiktā periodā.
| mazs | vidēji | liels | |
| 48 | 47 | 46 | |
| 50 | 61 | 57 | |
| 63 | 63 | 57 | |
| 72 | 47 | 55 | |
| 43 | 32 | ||
| 59 | 59 | ||
| 58 | |||
| Vidēji | 58,6 | 54,0 | 51,0 |
| Izkliede | 128,25 | 65,00 | 107,60 |
Faktoru gradācijas klašu (grupu) skaits a= 3 , novērojumu skaits klasēs (grupās) n1 = 4 , n2 = 7 , n3 = 6 . Kopējais novērojumu skaits n = 17 .
Brīvības pakāpju skaitļi:
va = a − 1 = 2 ,
ve= n − a = 17 − 3 = 14 ,
v = n − 1 = 16 .
Aprēķināsim noviržu kvadrātu summas:




Aprēķināsim novirzes:
![]() ,
,
![]() .
.
Aprēķināsim faktisko Fišera attiecību:
![]() .
.
Fišera koeficienta kritiskā vērtība:
Tā kā Fišera koeficienta faktiskā vērtība ir mazāka par kritisko: , secinām, ka uzņēmuma vienības lielums būtiski neietekmē ražošanas izmaksas.
Vai arī, kas ir tas pats, ar 95% varbūtību mēs pieņemam galveno hipotēzi, ka vienas un tās pašas preces vienības ražošanas vidējās izmaksas mazās, vidējās un lielās uzņēmuma nodaļās būtiski neatšķiras.
Vienvirziena ANOVA programmā MS Excel
Vienvirziena dispersijas analīzi var veikt, izmantojot MS Excel procedūru Vienvirziena dispersijas analīze. Mēs to izmantojam, lai analizētu datus par saistību starp izmantoto izejvielu veidu un uzņēmuma peļņu no 1. piemēra.
Pakalpojumu/datu analīze un izvēlieties analīzes rīku Vienvirziena dispersijas analīze.
logā ievades intervāls norādiet datu apgabalu (mūsu gadījumā tas ir $A$2:$E$7). Mēs norādām, kā faktors tiek grupēts - pēc kolonnām vai rindām (mūsu gadījumā pēc rindām). Ja pirmajā kolonnā ir faktoru klašu nosaukumi, atzīmējiet izvēles rūtiņu Etiķetes pirmajā kolonnā. Logā Alfa norāda nozīmīguma līmeni α = 0,05 .



Otrajā tabulā - dispersijas analīze - ir dati par faktora vērtībām starp grupām un grupām un summām. Tie ir noviržu kvadrātā (SS), brīvības pakāpju skaits (df) un dispersija (MS). Pēdējās trīs ailēs - Fišera koeficienta faktiskā vērtība (F), p-līmenis (P-vērtība) un Fišera koeficienta kritiskā vērtība (F crit).
| JAUNKUNDZE | F | p-vērtība | Fcrit |
| 0,58585 | 6,891119 | 0,000936 | 2,77285 |
| 0,085017 | |||
Tā kā Fišera koeficienta faktiskā vērtība (6,89) ir lielāka par kritisko vērtību (2,77), ar 95% varbūtību mēs noraidām nulles hipotēzi par vidējās produktivitātes vienādību, izmantojot visu veidu izejvielas, tas ir, mēs secināt, ka izmantoto izejvielu veids ietekmē peļņas uzņēmumus.
Divvirzienu dispersijas analīze bez atkārtojumiem: metodes būtība, formulas, piemērs
Divvirzienu dispersijas analīze tiek izmantota, lai pārbaudītu efektīvās pazīmes iespējamo atkarību no diviem faktoriem: A Un B. Tad a- faktora gradāciju skaits A Un b- faktora gradāciju skaits B. Statistikas kompleksā atlikuma kvadrātu summa ir sadalīta trīs komponentos:
SS = SS a + SS b + SS e,
![]() ir noviržu kvadrātā kopējā summa,
ir noviržu kvadrātā kopējā summa,
![]() - skaidro ar faktora ietekmi A noviržu kvadrātā summa,
- skaidro ar faktora ietekmi A noviržu kvadrātā summa,
![]() - skaidro ar faktora ietekmi B noviržu kvadrātā summa,
- skaidro ar faktora ietekmi B noviržu kvadrātā summa,
![]()
![]() - kopējais novērojumu vidējais rādītājs,
- kopējais novērojumu vidējais rādītājs,
Novērojumu vidējais rādītājs katrā faktora pakāpē A ,
B .
A ,
Izkliede izskaidrojama ar faktora ietekmi B ,
![]()
va = a − 1 A ,
vb= b − 1 - dispersijas brīvības pakāpju skaits, kas izskaidrojams ar faktora ietekmi B ,
ve = ( a − 1)(b − 1)
v = ab− 1 - kopējais brīvības pakāpju skaits.
Ja faktori ir neatkarīgi viens no otra, tad faktoru nozīmīguma noteikšanai tiek izvirzītas divas nulles hipotēzes un atbilstošās alternatīvās hipotēzes:
par faktoru A :
H0 : μ 1A= μ 2A = ... = μ aA,
H1 : Ne viss μ iA ir vienādi;
par faktoru B :
H0 : μ 1B= μ 2B=...= μ aB,
H1 : Ne viss μ iB ir vienādi.
A
Lai noteiktu faktora ietekmi B, mums ir jāsalīdzina faktiskā Fišera attiecība ar kritisko Fišera koeficientu.
α P = 1 − α .
α P = 1 − α .
Divvirzienu dispersijas analīze bez atkārtojumiem: piemērs
3. piemērs Tiek sniegta informācija par vidējo degvielas patēriņu uz 100 kilometriem litros atkarībā no dzinēja izmēra un degvielas veida.
Jāpārbauda, vai degvielas patēriņš ir atkarīgs no dzinēja izmēra un degvielas veida.
Risinājums. Par faktoru A gradācijas klašu skaits a= 3 , koeficientam B gradācijas klašu skaits b = 3 .
Mēs aprēķinām noviržu kvadrātu summas:
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
Attiecīgās novirzes:
![]() ,
,
![]() ,
,
![]() .
.
A
![]()
![]() . Tā kā faktiskais Fišera koeficients ir mazāks par kritisko, ar 95% varbūtību mēs pieņemam hipotēzi, ka dzinēja izmērs neietekmē degvielas patēriņu. Taču, ja izvēlamies nozīmīguma līmeni α
= 0,1 , tad Fišera koeficienta faktiskā vērtība un tad ar 95% varbūtību varam pieņemt, ka dzinēja izmērs ietekmē degvielas patēriņu.
. Tā kā faktiskais Fišera koeficients ir mazāks par kritisko, ar 95% varbūtību mēs pieņemam hipotēzi, ka dzinēja izmērs neietekmē degvielas patēriņu. Taču, ja izvēlamies nozīmīguma līmeni α
= 0,1 , tad Fišera koeficienta faktiskā vērtība un tad ar 95% varbūtību varam pieņemt, ka dzinēja izmērs ietekmē degvielas patēriņu.
Faktiskā Fišera koeficients faktoram B
![]() , Fišera koeficienta kritiskā vērtība:
, Fišera koeficienta kritiskā vērtība: ![]() . Tā kā faktiskā Fišera koeficients ir lielāks par Fišera koeficienta kritisko vērtību, mēs ar 95% varbūtību pieņemam, ka degvielas veids ietekmē tās patēriņu.
. Tā kā faktiskā Fišera koeficients ir lielāks par Fišera koeficienta kritisko vērtību, mēs ar 95% varbūtību pieņemam, ka degvielas veids ietekmē tās patēriņu.

Divvirzienu dispersijas analīze bez atkārtojumiem programmā MS Excel
Divvirzienu dispersijas analīzi bez atkārtojumiem var veikt, izmantojot MS Excel procedūru. Mēs to izmantojam, lai analizētu datus par saistību starp degvielas veidu un tās patēriņu no 3. piemēra.
MS Excel izvēlnē izpildiet komandu Pakalpojumu/datu analīze un izvēlieties analīzes rīku Divvirzienu dispersijas analīze bez atkārtojumiem.
Datus aizpildām tāpat kā vienvirziena ANOVA gadījumā.

Procedūras rezultātā tiek parādītas divas tabulas. Pirmā tabula ir Kopējie. Tas satur datus par visām faktoru gradācijas klasēm: novērojumu skaitu, kopējo vērtību, vidējo vērtību un dispersiju.

Otrajā tabulā - Analysis of Variance - ir dati par izmaiņu avotiem: izkliede starp rindām, izkliede starp kolonnām, kļūdu izkliede, kopējā izkliede, noviržu kvadrātā (SS), brīvības pakāpju skaits (df), dispersija (MS). ). Pēdējās trīs ailēs - Fišera koeficienta faktiskā vērtība (F), p-līmenis (P-vērtība) un Fišera koeficienta kritiskā vērtība (F crit).
| JAUNKUNDZE | F | p-vērtība | Fcrit |
| 3,13 | 5,275281 | 0,075572 | 6,94476 |
| 8,043333 | 13,55618 | 0,016529 | 6,944276 |
| 0,593333 | |||
Faktors A(dzinēja izmērs) ir sagrupēts rindās. Tā kā faktiskais Fišera koeficients 5,28 ir mazāks par kritisko 6,94, mēs ar 95% varbūtību pieņemam, ka degvielas patēriņš nav atkarīgs no dzinēja izmēra.
Faktors B(degvielas veids) ir sagrupēts kolonnās. Faktiskais Fišera koeficients 13,56 ir lielāks par kritisko koeficientu 6,94, tāpēc ar 95% varbūtību pieņemam, ka degvielas patēriņš ir atkarīgs no tā veida.
Divvirzienu dispersijas analīze ar atkārtojumiem: metodes būtība, formulas, piemērs
Divvirzienu dispersijas analīze ar atkārtojumiem tiek izmantota, lai pārbaudītu ne tikai efektīvās pazīmes iespējamo atkarību no diviem faktoriem - A Un B, bet arī iespējamo faktoru mijiedarbību A Un B. Tad a- faktora gradāciju skaits A Un b- faktora gradāciju skaits B, r- atkārtojumu skaits. Statistikas kompleksā atlikumu kvadrātā summa ir sadalīta četrās komponentēs:
SS = SS a + SS b + SS ab + SS e,
![]() ir noviržu kvadrātā kopējā summa,
ir noviržu kvadrātā kopējā summa,
![]() - skaidro ar faktora ietekmi A noviržu kvadrātā summa,
- skaidro ar faktora ietekmi A noviržu kvadrātā summa,
![]() - skaidro ar faktora ietekmi B noviržu kvadrātā summa,
- skaidro ar faktora ietekmi B noviržu kvadrātā summa,
![]() - skaidrojams ar faktoru mijiedarbības ietekmi A Un B noviržu kvadrātā summa,
- skaidrojams ar faktoru mijiedarbības ietekmi A Un B noviržu kvadrātā summa,
![]() - neizskaidrojama noviržu kvadrātā vai kļūdu kvadrātu summa,
- neizskaidrojama noviržu kvadrātā vai kļūdu kvadrātu summa,
![]() - kopējais novērojumu vidējais rādītājs,
- kopējais novērojumu vidējais rādītājs,
![]() - novērojumu vidējais rādītājs katrā faktora pakāpē A
,
- novērojumu vidējais rādītājs katrā faktora pakāpē A
,
![]() - vidējais novērojumu skaits katrā faktora gradācijā B
,
- vidējais novērojumu skaits katrā faktora gradācijā B
,
Vidējais novērojumu skaits katrā faktoru gradāciju kombinācijā A Un B ,
n = abr ir kopējais novērojumu skaits.
Novirzes tiek aprēķinātas šādi:
Izkliede izskaidrojama ar faktora ietekmi A ,
Izkliede izskaidrojama ar faktora ietekmi B ,
![]() - izkliede, ko izskaidro faktoru mijiedarbība A Un B
,
- izkliede, ko izskaidro faktoru mijiedarbība A Un B
,
![]() - neizskaidrojama novirze vai kļūdu novirze,
- neizskaidrojama novirze vai kļūdu novirze,
va = a − 1 - dispersijas brīvības pakāpju skaits, kas izskaidrojams ar faktora ietekmi A ,
vb= b − 1 - dispersijas brīvības pakāpju skaits, kas izskaidrojams ar faktora ietekmi B ,
vab = ( a − 1)(b − 1) - dispersijas brīvības pakāpju skaits, kas izskaidrojams ar faktoru mijiedarbību A Un B ,
ve= ab(r − 1) ir neizskaidrojamas vai kļūdas dispersijas brīvības pakāpju skaits,
v = abr− 1 - kopējais brīvības pakāpju skaits.
Ja faktori ir neatkarīgi viens no otra, tad faktoru nozīmīguma noteikšanai tiek izvirzītas trīs nulles hipotēzes un atbilstošās alternatīvās hipotēzes:
par faktoru A :
H0 : μ 1A= μ 2A = ... = μ aA,
H1 : Ne viss μ iA ir vienādi;
par faktoru B :
Noteikt faktoru mijiedarbības ietekmi A Un B, mums ir jāsalīdzina faktiskā Fišera attiecība ar kritisko Fišera koeficientu.
Ja faktiskā Fišera attiecība ir lielāka par kritisko Fišera koeficientu, nulles hipotēze jānoraida ar nozīmīguma līmeni α . Tas nozīmē, ka faktors būtiski ietekmē datus: dati ir atkarīgi no faktora ar varbūtību P = 1 − α .
Ja faktiskā Fišera attiecība ir mazāka par kritisko Fišera koeficientu, tad nulles hipotēze ir jāpieņem ar nozīmīguma līmeni α . Tas nozīmē, ka faktors būtiski neietekmē datus ar varbūtību P = 1 − α .
Divvirzienu dispersijas analīze ar atkārtojumiem: piemērs
par faktoru mijiedarbību A Un B: faktiskais Fišera koeficients ir mazāks par kritisko, tāpēc reklāmas kampaņas un konkrētā veikala mijiedarbība nav būtiska.
Divvirzienu dispersijas analīze ar atkārtojumiem programmā MS Excel
Divvirzienu dispersijas analīzi ar atkārtojumiem var veikt, izmantojot MS Excel procedūru. Mēs to izmantojam, lai analizētu datus par saistību starp veikala ienākumiem un konkrēta veikala izvēli un reklāmas kampaņu no 4. piemēra.
MS Excel izvēlnē izpildiet komandu Pakalpojumu/datu analīze un izvēlieties analīzes rīku Divvirzienu dispersijas analīze ar atkārtojumiem.
Mēs aizpildām datus tāpat kā divvirzienu ANOVA bez atkārtojumiem, pievienojot to, ka parauga lodziņā ir jāievada atkārtojumu skaits.

Procedūras rezultātā tiek parādītas divas tabulas. Pirmā tabula sastāv no trim daļām: pirmās divas atbilst katrai no divām reklāmas kampaņām, trešajā ir dati par abām reklāmas kampaņām. Tabulas ailēs ir informācija par visām otrā faktora gradācijas klasēm - krātuve: novērojumu skaits, kopējā vērtība, vidējā vērtība un dispersija.

Otrajā tabulā - dati par noviržu kvadrātā (SS), brīvības pakāpju skaitu (df), dispersiju (MS), Fišera koeficienta faktisko vērtību (F), p-līmeni (P-vērtība) un Fišera koeficienta kritiskā vērtība (F crit) dažādiem izmaiņu avotiem: divi faktori, kas norādīti rindās (izlase) un kolonnās, faktoru mijiedarbība, kļūdas (iekšā) un kopsummas (kopā).
| JAUNKUNDZE | F | p-vērtība | Fcrit |
| 8,013339 | 0,500252 | 0,492897 | 4,747221 |
| 189,1904 | 11,81066 | 0,001462 | 3,88529 |
| 6,925272 | 0,432327 | 0,658717 | 3,88529 |
| 16,01861 | |||
Par faktoru B faktiskais Fišera koeficients ir lielāks par kritisko koeficientu, tāpēc ar varbūtību 95%, ieņēmumi dažādos veikalos ievērojami atšķiras.
Par faktoru mijiedarbību A Un B faktiskais Fišera koeficients ir mazāks par kritisko, tāpēc ar 95% varbūtību reklāmas kampaņas un konkrētā veikala mijiedarbība nav būtiska.
Viss par "matemātisko statistiku"
Šajā rakstā ir apskatīta dispersijas analīze. Izanalizētas tās pielietojuma raksturīgās iezīmes, sniegtas dispersijas analīzes metodes, dispersijas analīzes piemērošanas nosacījumi. Tiek atklāta un pamatota šīs metodes izmantošanas nepieciešamība. Pamatojoties uz pētījumu, ir sniegti klasiskās dispersijas analīzes posmi.
- Jautājumā par automašīnu kvalitātes kontroles nodrošināšanu pēc remontdarbu veikšanas autoservisa uzņēmumos, ņemot vērā sertifikācijas sistēmas prasības
- Informācijas tehnoloģiju ieviešanas problēmas loģistikā uz Krievijas organizāciju piemēra
- Viļņu ģeneratoru komplekta efektivitātes uzlabošana
- Izglītības un metodiskā rokasgrāmata "Zemes-Mēness sistēma" tālmācības sistēmā Moodle
Dispersijas analīzes galvenais mērķis ir izpētīt vidējo atšķirības nozīmīgumu. Ja jūs tikai salīdzinat divu paraugu vidējos rādītājus, dispersijas analīze sniegs tādu pašu rezultātu kā parastā analīze. t- neatkarīgu paraugu tests (tas ir, ja tiek salīdzinātas divas neatkarīgas objektu vai novērojumu grupas) vai t-tests atkarīgiem paraugiem (tas ir, ja tiek salīdzināti divi mainīgie vienā un tajā pašā objektu vai novērojumu kopā).
Dispersijas analīzei šāds nosaukums ir saistībā ar dažiem faktoriem. Var šķist dīvaini, ka vidējo salīdzināšanas procedūru sauc par dispersijas analīzi. Faktiski tas ir saistīts ar faktu, ka, pārbaudot statistisko nozīmīgumu atšķirībai starp divu (vai vairāku) grupu vidējiem rādītājiem, mēs faktiski salīdzinām (t.i., analizējam) izlases dispersijas. Dispersijas analīzes pamatjēdzienu Fišers ierosināja 1920. gadā. Iespējams, dabiskāks termins būtu kvadrātu summas analīze vai variāciju analīze, taču tradīciju dēļ tiek lietots termins dispersijas analīze.
Dispersijas analīze ir matemātiskās statistikas metode, kuras mērķis ir atrast atkarības eksperimentālajos datos, pārbaudot vidējo vērtību atšķirību nozīmīgumu. Atšķirībā no t-testa, tas ļauj salīdzināt trīs vai vairāku grupu vidējos rādītājus. Izstrādājis R. Fišers, lai analizētu eksperimentālo pētījumu rezultātus. Literatūrā ir arī apzīmējums ANOVA (no angļu valodas. dispersijas analīze).
Veicot tirgus izpēti, bieži rodas jautājums par rezultātu salīdzināmību. Piemēram, veicot aptaujas par noteiktas preces patēriņu dažādos valsts reģionos, ir jāizdara secinājumi, ar ko aptaujas dati atšķiras vai neatšķiras savā starpā. Nav jēgas salīdzināt atsevišķus rādītājus, tāpēc salīdzināšanas un turpmākā novērtējuma procedūra tiek veikta saskaņā ar dažām vidējām vērtībām un novirzēm no šī vidējā novērtējuma. Pazīmes variācija tiek pētīta. Variāciju var uzskatīt par variācijas mēru. Izkliede σ 2 ir variācijas mērs, kas definēts kā pazīmes noviržu vidējā vērtība kvadrātā.
Praksē bieži rodas vispārīgāka rakstura uzdevumi - vairāku izlases paraugu vidējo rādītāju atšķirību nozīmīguma pārbaudes uzdevumi. Piemēram, nepieciešams izvērtēt dažādu izejvielu ietekmi uz produkcijas kvalitāti, risināt problēmu par mēslošanas līdzekļu daudzuma ietekmi uz lauksaimniecības kultūru ražu. produktiem.
Dažkārt dispersijas analīzi izmanto, lai noteiktu vairāku populāciju viendabīgumu (šo populāciju dispersijas pēc pieņēmuma ir vienādas; ja dispersijas analīze parāda, ka matemātiskās cerības ir vienādas, tad populācijas šajā ziņā ir viendabīgas). Homogēnās populācijas var apvienot vienā un tādējādi iegūt par to pilnīgāku informāciju un līdz ar to ticamākus secinājumus.
ANOVA METODES
- Fišera metode - F kritērijs; Metode tiek izmantota vienvirziena dispersijas analīzē, kad visu novēroto vērtību kopējā dispersija tiek sadalīta dispersijā atsevišķu grupu ietvaros un dispersijā starp grupām.
- "Vispārējā lineārā modeļa" metode. Tas ir balstīts uz korelācijas vai regresijas analīzi, ko izmanto daudzfaktoru analīzē.
Viena faktora dispersijas modelim ir šāda forma: x ij = μ + F j + ε ij ,
kur х ij ir pētāmā mainīgā vērtība, kas iegūta faktora i-tajā līmenī (i=1,2,...,т) ar j-to kārtas numuru (j=1,2,... ,n); F i ir efekts, ko rada faktora i-tā līmeņa ietekme; ε ij ir nejauša sastāvdaļa jeb traucējums, ko izraisa nekontrolējamu faktoru ietekme, t.i. variācijas vienā līmenī.
Vienkāršākais dispersijas analīzes gadījums ir viendimensijas vienvirziena analīze divām vai vairākām neatkarīgām grupām, kad visas grupas tiek apvienotas pēc viena atribūta. Analīzes laikā tiek pārbaudīta nulles hipotēze par vidējo vienlīdzību. Analizējot divas grupas, dispersijas analīze ir identiska divu paraugu analīzei t-Studenta kritērijs neatkarīgiem paraugiem un vērtība F-statistika ir vienāda ar atbilstošās kvadrātu t- statistika.
Lai apstiprinātu apgalvojumu par dispersiju vienādību, parasti tiek izmantots Līvena kritērijs ( Levēna tests). Ja hipotēze par dispersiju vienādību tiek noraidīta, galvenā analīze nav piemērojama. Ja dispersijas ir vienādas, tad, lai novērtētu starpgrupu un starpgrupu mainīguma attiecību, F- Fišera kritērijs.Ja F-statistika pārsniedz kritisko vērtību, tad nulles hipotēze tiek noraidīta un tiek izdarīts secinājums par vidējo nevienlīdzību. Analizējot abu grupu vidējos rādītājus, rezultātus var interpretēt uzreiz pēc Fišera testa piemērošanas.
Daudz faktoru. Pasaule pēc savas būtības ir sarežģīta un daudzdimensionāla. Situācijas, kad kādu parādību pilnībā apraksta viens mainīgais lielums, ir ārkārtīgi reti. Piemēram, ja mēs cenšamies iemācīties audzēt lielus tomātus, mums jāņem vērā faktori, kas saistīti ar augu ģenētisko struktūru, augsnes tipu, gaismu, temperatūru utt. Tādējādi, veicot tipisku eksperimentu, jums ir jārisina liels skaits faktoru. Galvenais iemesls, kāpēc ir vēlams izmantot dispersijas analīzi, nevis atkārtoti salīdzināt divus paraugus dažādos faktoru līmeņos, izmantojot sērijas t- kritērijs ir tāds, ka dispersijas analīze ir daudz vairāk efektīvs un maziem paraugiem informatīvāks. Jums ir jāpieliek pūles, lai apgūtu STATISTICA ieviesto dispersijas analīzes tehniku un izjustu visas tās priekšrocības konkrētos pētījumos.
Divu faktoru dispersijas modelim ir šāda forma:
x ijk =μ+F i +G j +I ij +ε ijk ,
kur x ijk ir novērojuma vērtība šūnā ij ar skaitli k; μ - vispārējais vidējais; F i - efekts A faktora i-tā līmeņa ietekmes dēļ; G j - efekts faktora B j-tā līmeņa ietekmes dēļ; I ij - efekts divu faktoru mijiedarbības dēļ, t.i. novirze no vidējā novērojumiem šūnā ij no modeļa pirmo trīs terminu summas; ε ijk - traucējumi mainīgā lieluma variācijas dēļ vienā šūnā. Tiek pieņemts, ka ε ijk ir normāls sadalījums N(0; с 2), un visas matemātiskās cerības F * , G * , I i * , I * j ir vienādas ar nulli.
Dispersijas analīzes izmantošanai ir nosacījumi:
- Pētījuma uzdevums ir noteikt viena (līdz 3) faktora ietekmes stiprumu uz rezultātu vai noteikt dažādu faktoru (dzimuma un vecuma, fiziskās aktivitātes un uztura u.c.) kombinētās ietekmes stiprumu.
- Pētītajiem faktoriem jābūt neatkarīgiem (nesaistītiem) vienam ar otru. Piemēram, nevar pētīt darba pieredzes un bērnu vecuma, auguma un svara u.c. kopējo ietekmi. par iedzīvotāju saslimstību.
- Grupu atlase pētījumam tiek veikta nejauši (nejaušs atlase). Izkliedes kompleksa organizēšanu ar iespēju nejaušas izvēles principa ieviešanu sauc par randomizāciju (tulkojumā no angļu valodas - random), t.i. izvēlēts nejauši.
- Var izmantot gan kvantitatīvās, gan kvalitatīvās (atribūtīvās) pazīmes.
Veicot vienvirziena dispersijas analīzi, ieteicams (nepieciešams nosacījums lietošanai):
- Analizēto grupu sadalījuma normalitāte vai izlases grupu atbilstība vispārējām populācijām ar normālu sadalījumu.
- Novērojumu sadalījuma grupās neatkarība (nesavienotība).
- Novērojumu biežuma (atkārtošanās) klātbūtne.
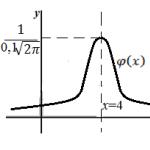
Sadalījuma normalitāti nosaka Gausa (De Mavour) līkne, ko var aprakstīt ar funkciju y \u003d f (x), jo tas ir viens no sadalījuma likumiem, ko izmanto, lai tuvinātu nejaušu parādību aprakstu, varbūtības raksturs. Biomedicīnas pētījumu priekšmets ir varbūtības rakstura parādības, normālais sadalījums šādos pētījumos ir ļoti izplatīts.
Klasiskā dispersijas analīze tiek veikta šādos posmos:
- Dispersijas kompleksa izbūve.
- Noviržu vidējo kvadrātu aprēķins.
- Distances aprēķins.
- Faktoru un atlikušo dispersiju salīdzinājums.
- Rezultātu novērtēšana, izmantojot Fišera-Snedekora sadalījuma teorētiskās vērtības
- Mūsdienu dispersijas analīzes pielietojumi aptver plašu problēmu loku ekonomikā, bioloģijā un tehnoloģijā, un tos parasti interpretē kā statistisko teoriju, kas atklāj sistemātiskas atšķirības starp tiešo mērījumu rezultātiem, kas veikti noteiktos mainīgos apstākļos.
- Pateicoties dispersijas analīzes automatizācijai, pētnieks var veikt dažādus statistikas pētījumus, izmantojot datorus, vienlaikus tērējot mazāk laika un pūļu datu aprēķiniem. Pašlaik ir daudz programmatūras pakotņu, kas ievieš dispersijas analīzes aparātu. Visizplatītākie ir tādi programmatūras produkti kā: MS Excel, Statistica; Stadia; SPSS.
Lielākā daļa statistikas metožu ir ieviestas mūsdienu statistikas programmatūras produktos. Attīstoties algoritmiskās programmēšanas valodām, radās iespēja izveidot papildu blokus statistikas datu apstrādei.
ANOVA ir jaudīga moderna statistikas metode eksperimentālo datu apstrādei un analīzei psiholoģijā, bioloģijā, medicīnā un citās zinātnēs. Tas ir ļoti cieši saistīts ar specifisko eksperimentālo pētījumu plānošanas un veikšanas metodiku.
Dispersijas analīze tiek izmantota visās zinātnisko pētījumu jomās, kur nepieciešams analizēt dažādu faktoru ietekmi uz pētāmo mainīgo.
Bibliogrāfija
- Ableeva, A. M. Novērtēšanas fondu fonda izveide federālā valsts izglītības standarta apstākļos [Teksts] / A. M. Ableeva, G. A. Salimova // Aktuālās sociālo, humanitāro, dabaszinātņu un tehnisko disciplīnu mācīšanas problēmas augstākās izglītības modernizācijas apstākļos izglītība: materiāli starptautiskā zinātniskā un metodiskā konference, 2014. gada 4.-5. aprīlis / Baškīrijas Valsts Agrārās universitātes Informācijas tehnoloģiju un vadības fakultāte. - Ufa, 2014. - S. 11-14.
- Ganieva, A.M. Nodarbinātības un bezdarba statistiskā analīze [Teksts] / A.M. Ganieva, T.N. Ļubova // Ekonomisko un statistisko pētījumu un informācijas tehnoloģiju aktualitātes: Sest. zinātnisks Art.: Veltīts Ekonomikas statistikas un informācijas sistēmu katedras / Baškīrijas Valsts agrārās universitātes 40. gadadienai. - Ufa, 2011. - S. 315-316.
- Ismagilovs, R. R. Radošā grupa - efektīva zinātnisko pētījumu organizēšanas forma augstākajā izglītībā [Teksts] / R. R. Ismagilov, M. Kh. Urazlin, D. R. Islamgulov // Reģiona zinātniski tehniskie un zinātniski-izglītojošie kompleksi: problēmas un attīstības perspektīvas : zinātniski praktiskās konferences materiāli / Baltkrievijas Republikas Zinātņu akadēmija, USATU. - Ufa, 1999. - S. 105-106.
- Islamgulovs, D.R. Uz kompetencēm balstīta pieeja mācīšanai: izglītības kvalitātes novērtējums [Teksts] / D.R. Islamgulovs, T.N. Ļubova, I.R. Islamgulova // Mūsdienu zinātnes biļetens. - 2015. - T. 7. - Nr. 1. - S. 62-69.
- Islamgulovs, D. R. Studentu pētnieciskais darbs ir svarīgākais speciālistu sagatavošanas elements agrārās augstskolā [Teksts] / D. R. Islamgulovs // Studentu praktiskās apmācības problēmas universitātē pašreizējā posmā un to risināšanas veidi: Seb. materiālu zinātniskā metode. Konf., 2007. gada 24. aprīlis / Baškīrijas Valsts Agrārā universitāte. - Ufa, 2007. - S. 20-22.
- Ļubova, T.N. Pamats federālā štata izglītības standarta ieviešanai ir uz kompetencēm balstīta pieeja [Teksts] / T.N. Ļubova, D.R. Islamgulovs, I.R. Islamgulova // NĀKOTNES PĒTĪJUMS - 2016: Materiāli XII starptautiskajai zinātniskajai un praktiskai konferencei, 2016. gada 15.-22. februāris. - Sofija: Byal GRAD-BG OOD, 2016. - 4. sējums Pedagoģijas zinātnes. – C. 80-85.
- Ļubova, T.N. Jauni izglītības standarti: ieviešanas iezīmes [Teksts] / T.N. Ļubova, D.R. Islamgulovs // Mūsdienu zinātnes biļetens. - 2015. - T. 7. - Nr. 1. - S. 79-84.
- Ļubova, T.N. Studentu patstāvīgā darba organizācija [Teksts] / T.N. Ļubova, D.R. Islamgulovs // Augstākās izglītības programmu īstenošana federālā valsts augstākās izglītības standarta ietvaros: Viskrievijas zinātniskās un metodiskās konferences materiāli NMS ietvaros par vides pārvaldību un federālā UMO ūdens izmantošanu augstākās izglītības sistēmā. / Baškīrijas Valsts Agrārā universitāte. - Ufa, 2016. - S. 214-219.
- Ļubova, T.N. Pamats federālā štata izglītības standarta ieviešanai ir uz kompetencēm balstīta pieeja [Teksts] / T.N. Ļubova, D.R. Islamgulovs, I.R. Islamgulova // Mūsdienu zinātnes biļetens. - 2015. - T. 7. - Nr. 1. - S. 85-93.
- Saubanova, L.M. Demogrāfiskās slodzes līmenis [Teksts] / L.M. Saubanova, T.N. Ļubova // Ekonomisko un statistisko pētījumu un informācijas tehnoloģiju aktualitātes: Sest. zinātnisks Art.: Veltīts Ekonomikas statistikas un informācijas sistēmu katedras / Baškīrijas Valsts agrārās universitātes 40. gadadienai. - Ufa, 2011. - S. 321-322.
- Fahrulina, A.R. Inflācijas statistiskā analīze Krievijā [Teksts] / A.R. Fahrulina, T.N. Ļubova // Ekonomisko un statistisko pētījumu un informācijas tehnoloģiju aktualitātes: Sest. zinātnisks Art.: Veltīts Ekonomikas statistikas un informācijas sistēmu katedras / Baškīrijas Valsts agrārās universitātes 40. gadadienai. - Ufa, 2011. - S. 323-324.
- Farkhutdinova, A.T. Darba tirgus Baškortostānas Republikā 2012. gadā [Elektroniskais resurss] / A.T. Farkhutdinova, T.N. Ļubova // Studentu zinātniskais forums. V Starptautiskās studentu elektroniskās zinātniskās konferences materiāli: elektroniskā zinātniskā konference (elektroniskais krājums). Krievijas Dabaszinātņu akadēmija. 2013. gads.
Saistītie raksti